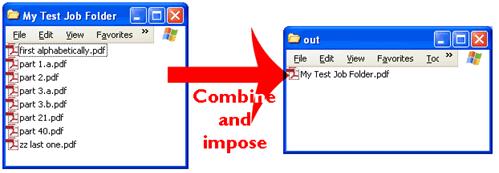
Combine files using job folders
Easily combine files by putting them together, in what we call a job folder. More details on http://www.quite.com/hotimposing/job_folders.htm
This function works in each mode of Quite Hot Imposing, as follows
- In Hot Folder mode, but you must switch on “Allow job folders” in setup screen 3. The job folder is found in the IN folder. When creating a job folder, this should not be done by creating the folder in the IN queue folder. The folder may be taken away and processed before you finished. Instead, create the folder (if possible, on the same disk) and move it into the IN folder.
- In command line (CLI) mode, the -source option can specify a folder.
- In Enfocus Switch, a folder is always accepted.
Only PDF files are combined. The combination uses a special order that splits the file names up, keeping numbers separate. This means that FILE1, FILE22, FILE101 are processed in that order, also FILE12PART1, FILE12PART22, FILE12PART101.
Certain other files and folders may be included.
- A control.xml file may appear. This overrides the XML or sequence which would otherwise apply. Note that this works only when using hot folders managed by Quite Hot Imposing, not with the command line (CLI) or Enfocus Switch.
- A REPLACE folder may appear, as described later. This provides replacements for PDF files used in the XML or sequence
- A file qivars.txt may give the value for variables. This is described in the separate documentation found on https://www.quite.com/hotimposing/vars/
Except as noted, nested files and directories are ignored.
Making multiple outputs with Split & Merge
Normally, a job writes exactly one file, the target. But there is one case where multiple files can be written. This is when the last step of the job uses the Split/Merge (Partials) command.
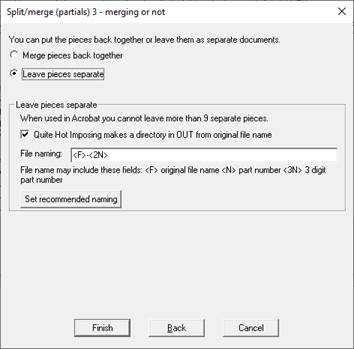
You can choose whether the split files are
- Joined back together – which makes a single target, and can be processed by further commands.
- Files are kept separate and saved. This must be the last step, no further commands can be used. There is no limit on the number of files in Quite Hot Imposing, but the limit is 9 in Quite Imposing Plus (and the files are not saved).
You can control the names of the files. Notice that there are also special codes such as <F>.
- <F> is the original file name (just the name part, without PDF).
- <N> is the split file number.
- <3N> is the split file number as 3 digits. You can set other digit counts.
- <C> is the count of pages in the part, or for example <4C> for a 4 digit number of the count of pages.
The file will always have .pdf added.
For example, a code of OUTFILE<2N>-<4C> would produce a file with a name like OUTFILE02-0048.pdf for the second split part with 48 pages. The original name is not used.
Notice the option “Quite Hot Imposing makes a directory in OUT from the original file name”.
- If this option is ON, a directory is created in the OUT folder. For example if the original file name was Leftjob2.pdf, the directory will be called Leftjob2. The split files are all written to this directory.
- If this option is OFF, no directory is created. All the separate files go directly into the OUT folder. We recommend that the name includes <F> otherwise it will not be possible to identify the original file, and files may be overwritten in OUT.
- In command line (CLI) mode the target file or directory for the command line defines the directory where the split files are written. Only the directory part is used, the filename is ignored. Either multiple files are written to that directory, or a subdirectory is created for the files, with name taken from the source file. There are more details in the command line specification.
- In Enfocus Switch mode, the result will be multiple files or a single folder, according to your settings.
Replacement files and datasets
Replacement files – Advanced automation (6.0)
Replacement files do not apply in the Quite Imposing Plus plug-in.
When automating work, it may be helpful to replace files used to set up a sequence or XML file. The files used include
- Background files
- Files for Insert Pages
- Files for Stick on Text
- Data source for Variable Data Merge (the replacement must have the same field names)
Replacement files allow you to create a file, typically with the same name as the original file, but in a different folder. You can then tell Quite Hot Imposing to use it. There are two ways to provide a replacement. A command line option, or a folder within a job folder.
- One or more of the command line options
- -replacefile filename
- -replacefile2 filetoreplace replacementfile
- -replacefilefolder replacementfolder
- The REPLACE subfolder in a job folder, provided as
- A folder dragged in the IN folder using Quite Hot Imposing watched folders (the queue must have “Allow job folders” set). This folder contains a REPLACE subfolder.
- A folder dragging into the input folder in Enfocus Switch (job folders are always allowed). This folder contains a REPLACE subfolder.
- A folder specified with the -source option in the Quite Hot Imposing command line. This folder contains a REPLACE subfolder.
When you use the command line option -replacefile filename then the file is added to a list. Whenever a file is to be used (background, data source etc.) the list is checked, and the replacement file is used if provided. That is, if the file in the XML or sequence has the same filename part as filename, then the replacement filename is used. The filename must include a directory unless it is in the current directory. If the file does not exist, but it would be used as a replacement, there will be an error.
When you use -replacefile2 filetoreplace replacementfile it is the same except that the original file in the XML or sequence will have the name in filetoreplace but the replacement replacementfile need not have the same name. As with -replacefile, the replacementfile must include a directory unless it is in the current directory, and must exist. But filetoreplace is only scanned to find a file name part; the file does not need to exist. Any file in the XML or sequence with the same name will be replaced.
When you use -replacefilefolder replacementfolder the folder replacementfolder is scanned. All files found there are specified as if with -replacefile filename.
When working with job folders, a folder is placed in the IN folder of Quite Hot Imposing, rather than a single PDF. The job folder contains one or more PDF files, and they will be joined together before running the sequence or XML files. You can create a subfolder REPLACE in the job folder, and provide replacement files inside that folder. This is the same as using -replacefilefolder sourcefolder\REPLACE (or /REPLACE on macOS).
An example of this is where a sequence has been set up to use a datasource of ADDRESSES.CSV. The job folder can have this structure
+MYJOB
FILE1.PDF
+REPLACE
ADDRESSES.CSV
The result file (written to the OUT folder) will be a single PDF called MYJOB.PDF. The entire job folder is moved to the DONE folder. A job folder can also be used via the command line, with -source jobfolder and with the Enfocus Switch configurator/app. It is your responsibility to make sure that the replacement file has the same columns as the original file.
Job folders are in earlier versions of Quite Hot Imposing, but they will ignore the REPLACE subfolder.
Datasets (Quite Hot Imposing Advanced feature for Enfocus Switch and command line) (6.0)
Datasets are simply a way of giving a special name to a file. At some point, you tell Quite Hot Imposing what actual file has this special name. For example, when you use Stick On PDF Pages you could add pages from a dataset “LOGOFILE”. Before you can make the result, you have to actually set a file for the LOGOFILE dataset, containing the logo needed for this particular job. Quite Hot Imposing will not go searching for a file called LOGOFILE, it's up to you to tell it what file to actually use and it will fail if you don’t do this.
There are two ways to set datasets. One is an automatic feature when used with Enfocus Switch. The other is a command line option. Datasets are not usually relevant when using Quite Hot Imposing with hot folders (though using Replacement Files with a Job Folder may give you a similar function).
To set a command to use a dataset, chose “Dataset…” in any command which accepts a file. This includes
- Stick on PDF pages
- Insert pages
- Page background for N-Up, Step & Repeat
- Variable data merge
Note that in variable data merge you need to choose a model file during the merge setup, to get the column names. It is your responsibility to make sure that the dataset has the same columns as the original model.
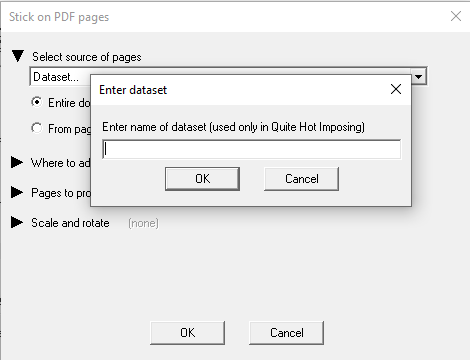
If you have referred to a dataset in a command, but not set up a dataset by that name, you will get a “File not found” error with a filename starting “Dataset:…”.
Use datasets with Enfocus Switch (6.0)
Datasets are a standard concept in Enfocus Switch. You can add datasets to a job to carry extra information. Often, script steps are added to a flow to create datasets. Recent versions of the Quite Hot Imposing configurator or app for Enfocus Switch have a new option “Connect Switch Metadata”. Set this to “Private data and datasets” and all the datasets in a flow are automatically added. (Note: Private data can be used to set variables in Quite Hot Imposing, this is described in a separate document).
Use datasets with the command line (6.0)
Datasets may be useful when Quite Hot Imposing is automated using the command line. The relevant command line options are as follows:
-dataset:dsname filename – this defines a dataset called dsname which should match a name used in a command (though there is no error for unused datasets).
The following probably only make sense if you are providing a separate interface to set datasets.
-replacefileds filename dsname – this allows you to use a dataset reference when a command was set up to use a regular file. The filename is the name part, without directory. This does not define the dataset, so you would also typically include -dataset:dsname newfilename. These two options would be more simply done using -replacefile2 filename newfilename. See the section on using replacement files for more details on this feature.
-vars dataset:dsname – this allows you to specify a list of variables is read from a specified dataset, rather than a filename.
Quite Hot Imposing – variables (advanced feature) (6.0)
Variables can be used so you can change the values in setup. So you could change rows, columns, page width, number of copies, caption to add to sheet, or many other elements that were fixed.
Variables can be set in a number of ways, including
- In the filename (such as Step advert-2-4.pdf for rows 2 and columns 4)
- In a file travelling along with the PDF
- With command line options
- With Enfocus Switch private data, or XML format datasets from submit points
Calculations are possible, and results can be returned to variables (such as, maximum number of pages on a sheet).
Full documentation and movies are on https://www.quite.com/hotimposing/vars/.